DAT DHCP Snooping¶
Problem Scenario¶

Many ARP Requests from a batman-adv gateway server
In larger mesh networks a significant (~30 kbit/s with ~1000 nodes) amount of ARP Requests can be observed. These are mostly broadcasted from nodes configured as a gateway and DHCP server.
The batman-adv Distributed ARP Table so far is unable to reduce the broadcast overhead for these specific ARP Requests from gateways.
Statistics¶
The following statistics were gathered at Freifunk Ostholstein on one of their gateway servers. Their mesh network consists of 300 nodes. The statistics show some details regarding the ARP Requests this specific gateway (a2:d9:c8:47:67:5d) generated:
$ ./summary.sh arp-1498963406-stage13.db a2:d9:c8:47:67:5d
# Summary
Statistics for ARP Requests from/on a2:d9:c8:47:67:5d
Duration: 0.581819 days
Total: 282190 (100%)
- via DAT BCAST: 252837 (89.5981%)
- answered: 32568 (12.881%)
- unanswered: 220269 (87.119%)
- via DAT Cache: 28672 (10.1605%)
- via DAT UCAST: 681 (0.241327%)
- bcast but missing ucast try (*): 0 (0%)
Total: 282190 (100%)
- Unanswered: 220271 (78.0577%)
- ok: 220269 (99.9991%)
- last reply: 212863 (96.6377%)
- 0-1 min.: 4250 (1.99659%)
- 1-3 min.: 33334 (15.6598%)
- 3-5 min.: 27789 (13.0549%)
- 5-10 min.: 30820 (14.4788%)
- 10-15 min.: 33372 (15.6777%)
- 15-20 min.: 29685 (13.9456%)
- 20-25 min.: 24080 (11.3124%)
- 25-30 min.: 11882 (5.58199%)
- 30-45 min.: 13278 (6.23781%)
- 45-60 min.: 2135 (1.00299%)
- 60-90 min.: 1527 (0.717363%)
- 90- min.: 711 (0.334018%)
- new: 7406 (3.36225%)
- missing ucast try (*): 0 (0%)
- missing bcast try (*): 2 (0.000907972%)
- Answered: 61919 (21.9423%)
- via DAT Cache: 28672 (46.3057%)
- via DAT UCAST: 679 (1.09659%)
- via DAT BCAST: 32568 (52.5977%)
- bcast but missing ucast try (*): 0 (0%)
via DAT Cache: Neither an ARP Request via unicast nor via broadcast
was observed on the underlying interface. Therefore
assuming the DAT Cache had answered.
via DAT UCAST: One or more ARP Requests via unicast but none via
broadcast were observed on the underlying interface.
Therefore assuming they successfully triggered the
ARP Reply.
via DAT BCAST: Both one or more ARP Requests via unicast and one
via broadcast were observed on the underlying interface.
Therefore assuming the broadcast had triggered the
ARP Reply.
last reply: How many minutes ago was an ARP Reply last seen on
upper/bat device.
(*): For a specific ARP Request observed on bat0, some expected
ARP Request(s) on the underlying interface were missed.
Focussing on the top statistics first:
Total: 282190 (100%)
- via DAT BCAST: 252837 (89.5981%)
- answered: 32568 (12.881%)
- unanswered: 220269 (87.119%)
- via DAT Cache: 28672 (10.1605%)
- via DAT UCAST: 681 (0.241327%)
- bcast but missing ucast try (*): 0 (0%)
Here there are two interesting points:
A) Nearly 90% of all ARP Requests this gateway sent were falling back to a batman-adv broadcast.
B) Of those 90%, 87% were left unanswered.
So it seems that there were some necessary and successful broadcasts. But the larger portion did not help in resolving the address.
The more detailed timing statistics indicate that of those unanswered ARP requests more than 95% are clients which were resolved successfully before.
Explanations¶
Unanswered ARP Request broadcasts¶
Freifunk networks are open and highly dynamic regarding their clients devices. A bus stopping near a Freifunk node might easily create a few dozen new connections and participants. And those ones will vanish shortly after.
Such dynamics might explain a large amount of unanswered, but previously successful ARP Requests.
Answered ARP Request broadcasts¶
The DAT_ENTRY_TIMEOUT is currently 5 minutes. Since ARP usually does not proactively send unsolicited ARP Replies there needs to be some ARP Request to query a client to refresh the DAT DHT.
So even if a client device has a stable IP and position it will likely result in a broadcasted ARP Request every five minutes.
Solution¶
Patches:DHCP Snooping¶
Status: merged upstream
The first patch provides an alternative to filling the DAT DHT: It allows learning IP-MAC pairs not only via ARP spoofing but DHCP spoofing, too. The advantage is that for DHCP we already have the gateway feature which always uses unicast transmissions.
Noflood mark¶
Status: rejected (some opinion(s) were that it would be nice to have a more complete filter architecture, also this is not that straightforward/foolproof to administrate/configure)
_
The second patch allows to prevent forwarding a frame which batman-adv would otherwise flood. With a DHCP snooping in place and a lease timeout lower than the 5min. DAT timeout ARP Requests for addresses in the DHCP range can safely be dropped. The noflood mark can be configured like:
$ echo 0x4/0x4 > /sys/class/net/bat0/mesh/noflood_mark
$ brctl addbr br0
$ brctl addif br0 bat0
$ ebtables -p ARP --logical-out br0 -o bat0 --arp-op Request --arp-ip-dst 10.84.0.0/29 -j ACCEPT
$ ebtables -p ARP --logical-out br0 -o bat0 --arp-op Request --arp-ip-dst 10.84.0.0/24 -j mark --mark-set 0x4
[ set lease timeout to a low value ]
This would result in the address range of 10.84.0.8-10.84.0.255 being marked for "noflood", while excempting 10.84.0.0-10.84.0.7.
Result¶
The following picture shows the amount of broadcasted ARP Request traffic before and after applying and configuring these patches at Freifunk Darmstadt (800 batman-adv nodes):

At about 23:00 this feature was enabled in their network on all gateway servers. Since then it is running there with no issues reported so far.
A month later it still looks like this (note the scale):

And the result (daily average) in relation to other layer 2 broadcasts:

Solution 2)¶
(Update 2024-09-11)
Patches:
- https://patchwork.open-mesh.org/project/b.a.t.m.a.n./cover/20240911051259.23384-1-linus.luessing@c0d3.blue/
- https://patchwork.open-mesh.org/project/b.a.t.m.a.n./patch/20240911051813.23550-1-linus.luessing@c0d3.blue/
DAT Timeout Split + Increase¶
Splitting the one DAT cache into a local DAT cache and a DAT DHT cache. Then increasing the timeout for the latter from 5 min. to 30min.
Result¶
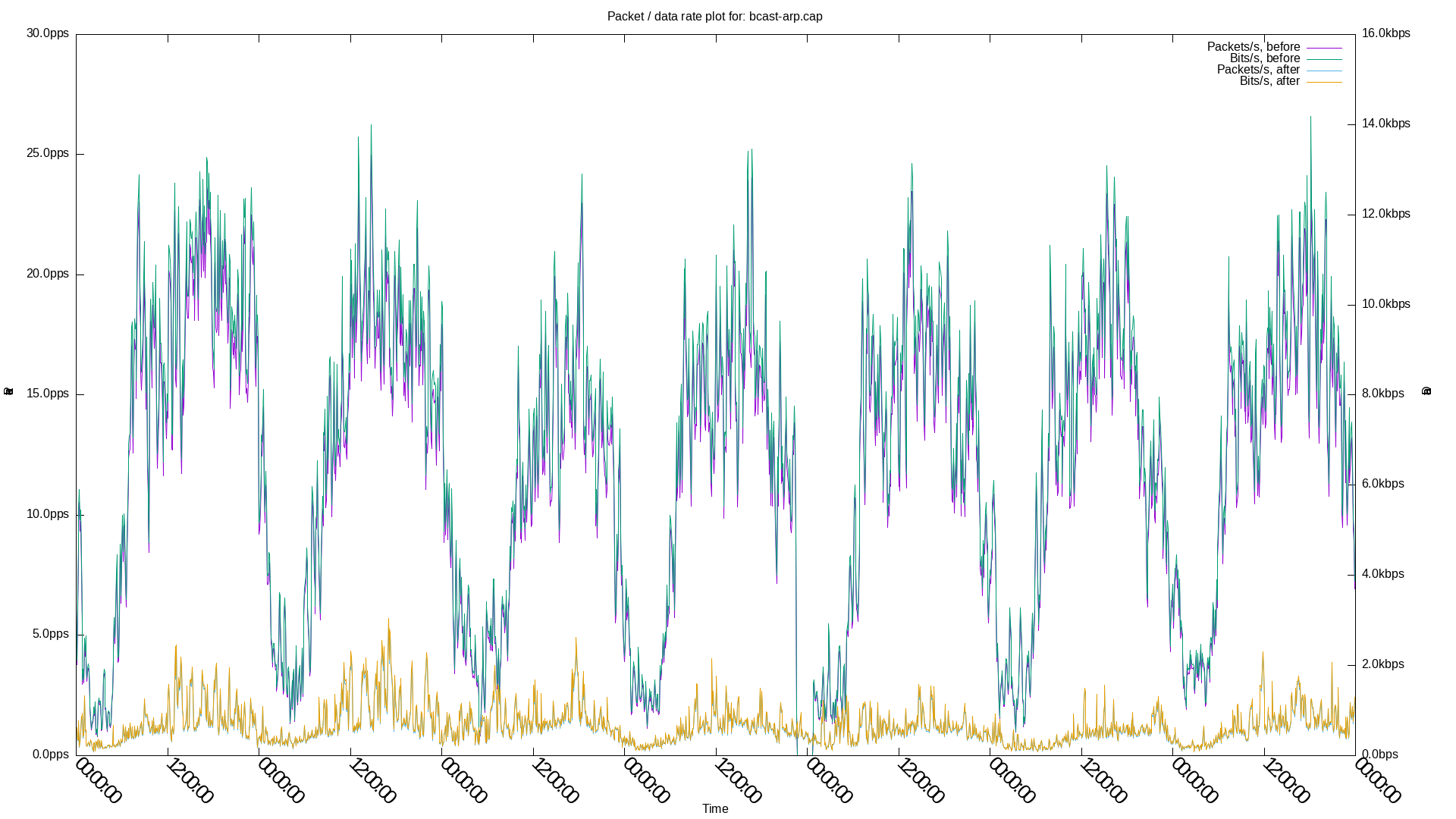
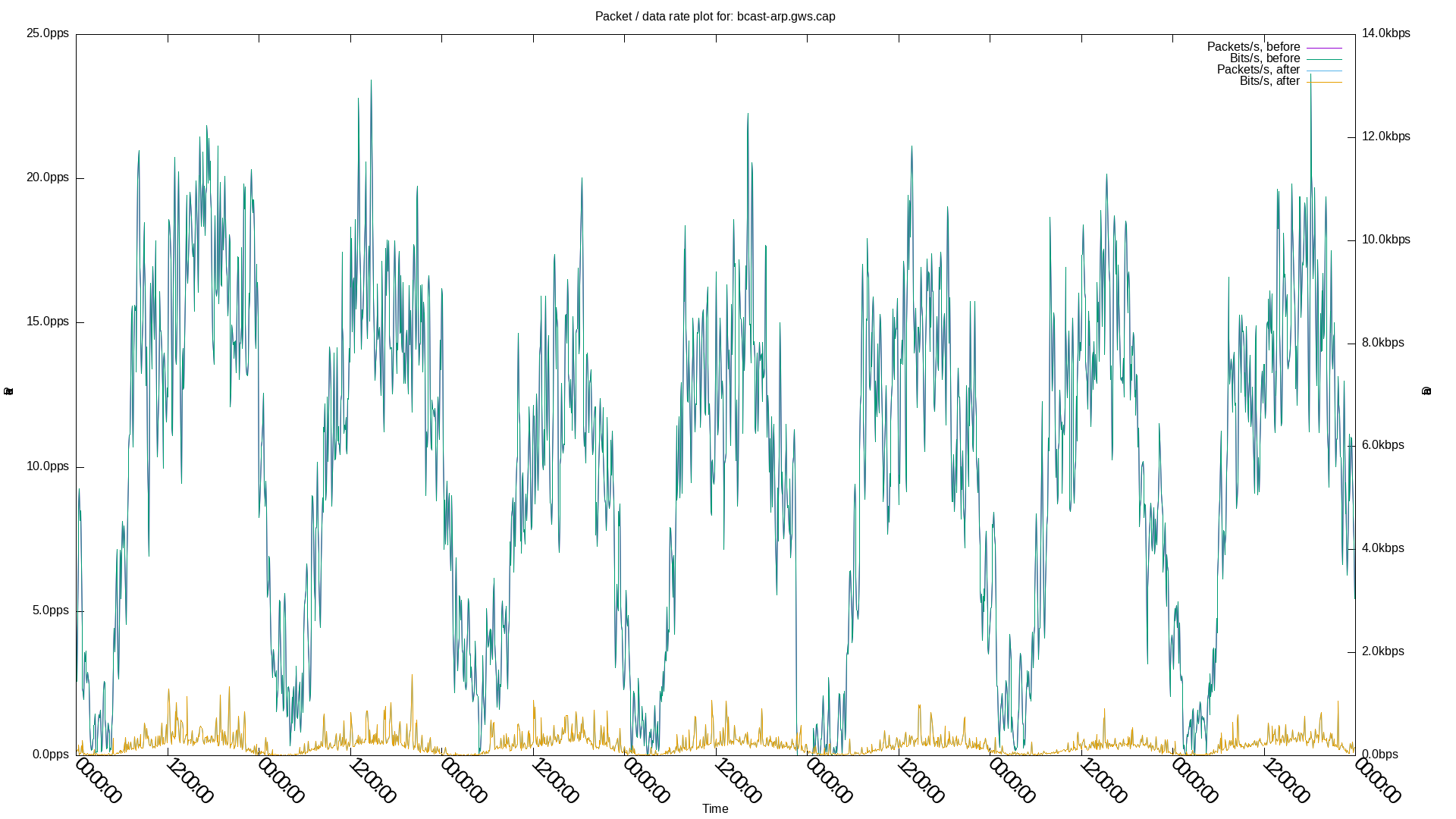
These two patches decreased the overall ARP broadcast overhead by 89.86% and the ARP broadcast overhead from gateways by 96.22% in a ~180 nodes setup at Freifunk Lübeck (firmware v0.19.0+v0.15.5, based on Gluon v2023.2.3 / OpenWrt 23.05 and batman-adv v2024.2), measured over one week before and after applying the patches on a specific mesh node's mesh-vpn interface.
Before:
- Broadcast ARP total: 6677.66 bits/s, 11.92 pkts/s
- from gateways: 5618.02 bits/s, 10.03 pkts/s
After:
- Broadcast ARP total: 677.26 bits/s (-89.86%), 1.21 pkts/s (-89.85%)
- from gateways: 212.28 bits/s (-96.22%), 0.38 pkts/s (-96.21%)
Broadcast ARP total, 7 days, before vs. after:
Broadcast ARP from gateways, 7 days, before vs. after:
More statistics¶
Before (average 2024-06-28T00:00:00+02:00 + 7 days):
# PCAP-file bits/s pkts/s
bcast-arp.cap,6677.66,11.92
bcast-arp.esps.cap,650.39,1.16
bcast-arp.esps.rep.cap,0.00,0.00
bcast-arp.esps.rep.grat.batbla.cap,0.00,0.00
bcast-arp.esps.rep.grat.cap,0.00,0.00
bcast-arp.esps.req.cap,650.39,1.16
bcast-arp.esps.req.grat.cap,0.00,0.00
bcast-arp.esps.req.probe.cap,0.01,0.00
bcast-arp.gws.cap,5618.02,10.03
bcast-arp.gws.rep.cap,0.00,0.00
bcast-arp.gws.rep.grat.batbla.cap,0.00,0.00
bcast-arp.gws.rep.grat.cap,0.00,0.00
bcast-arp.gws.req.cap,5618.02,10.03
bcast-arp.gws.req.grat.cap,0.00,0.00
bcast-arp.gws.req.probe.cap,0.00,0.00
bcast-arp.others.cap,409.25,0.72
bcast-arp.others.rep.cap,0.28,0.00
bcast-arp.others.rep.grat.batbla.cap,0.00,0.00
bcast-arp.others.rep.grat.cap,0.28,0.00
bcast-arp.others.req.cap,408.97,0.72
bcast-arp.others.req.grat.cap,0.00,0.00
bcast-arp.others.req.probe.cap,89.75,0.16
After (average 2024-08-06T00:00:00+02:00 + 7 days):
# PCAP-file bits/s pkts/s
bcast-arp.cap,677.26,1.21
bcast-arp.esps.cap,163.95,0.29
bcast-arp.esps.rep.cap,0.00,0.00
bcast-arp.esps.rep.grat.batbla.cap,0.00,0.00
bcast-arp.esps.rep.grat.cap,0.00,0.00
bcast-arp.esps.req.cap,163.95,0.29
bcast-arp.esps.req.grat.cap,0.00,0.00
bcast-arp.esps.req.probe.cap,0.00,0.00
bcast-arp.gws.cap,212.28,0.38
bcast-arp.gws.rep.cap,0.00,0.00
bcast-arp.gws.rep.grat.batbla.cap,0.00,0.00
bcast-arp.gws.rep.grat.cap,0.00,0.00
bcast-arp.gws.req.cap,212.28,0.38
bcast-arp.gws.req.grat.cap,0.00,0.00
bcast-arp.gws.req.probe.cap,0.00,0.00
bcast-arp.others.cap,301.05,0.54
bcast-arp.others.rep.cap,0.71,0.00
bcast-arp.others.rep.grat.batbla.cap,0.00,0.00
bcast-arp.others.rep.grat.cap,0.71,0.00
bcast-arp.others.req.cap,300.35,0.53
bcast-arp.others.req.grat.cap,0.00,0.00
bcast-arp.others.req.probe.cap,88.33,0.16
With the following hierarchical pcap filter rules:
%YAML 1.2
---
_rules:
bcast-arp: "batadv 15 bcast and arp"
gws: "batadv 15 bcast and arp and ether src de:ad:ca:fe:aa:aa or ether src de:ad:ca:fe:dd:aa or ether src de:ad:ca:fe:bb:aa"
esps: "batadv 15 bcast and arp and ether src ec:da:3b:aa:83:28 or ether src 64:e8:33:f4:4e:38 or ether src d4:f9:8d:01:0a:40 or ether src ec:da:3b:a8:e0:00"
others: "batadv 15 bcast and arp and not (ether src de:ad:ca:fe:aa:aa or ether src de:ad:ca:fe:dd:aa or ether src de:ad:ca:fe:bb:aa or ether src ec:da:3b:aa:83:28 or ether src 64:e8:33:f4:4e:38 or ether src d4:f9:8d:01:a:40 or ether src ec:da:3b:a8:e0:00)"
req: "batadv 15 bcast and arp and arp[6:2] = 0x0001"
rep: "batadv 15 bcast and arp and arp[6:2] = 0x0002"
grat: "batadv 15 bcast and arp and arp[14:4] = arp[24:4]"
probe: "batadv 15 bcast and arp and arp[14:4] = 0x00000000 and arp[18:4] = 0x00000000 and arp[22:2] = 0x0000"
batbla: "batadv 15 bcast and arp and arp[18:2] = 0xff43 and arp[20:1] = 0x05"
_output:
bcast-arp:
gws:
req:
grat:
probe:
rep:
grat:
batbla:
esps:
req:
grat:
probe:
rep:
grat:
batbla:
others:
req:
grat:
probe:
rep:
grat:
batbla:
One other interesting observation/note: The mentioned and tracked ESP devices above were regularly trying to reach a specific 10.130.x.255 address in our network. It seems that they have a broken IP stack implementation and even though DHCP offered them a /16 subnet, they seemed to wrongly assume a /24. Therefore likely wrongly trying to use/resolve 10.130.x.255 instead of our gateways at 10.130.0.250-255 for instance. The owner was contacted and seems to have disconnected some already.